一條慢查詢會造成什麼後果?之前我覺得不就是返回資料會慢一些嘛,使用者體驗變差一點而已?
其實遠遠不止,我經歷過幾次線上事故,有一次就是由一條 SQL 慢查詢導致的。
那次是一條 SQL 查詢耗時達到 2–3 秒「沒有命中索引,導致全表掃描」,由於是高頻查詢,併發一起來很快就把 DB 執行緒池打滿了,導致大量查詢請求堆積,DB 伺服器 CPU 長時間 100%+,大量請求 timeout…
最終系統崩潰,老闆登場!
可見,團隊如果對慢查詢不引起足夠的重視,風險是很大的。
經過那次事故我們老闆就說:誰的程式碼再出現類似事故,開發和部門主管一起走人,嚇唬得一大堆主管心裡慌慌,趕緊招了兩位 DBA 同事。
慢查詢,顧名思義,執行很慢的查詢。有多慢?超過 long_query_time 引數設定的時間閾值(預設 10s),就被認為是慢的,是需要改善的。慢查詢被記錄在慢查詢日誌裡。
慢查詢日誌預設是不開啟的,如果你需要改善 SQL 語句,就可以開啟這個功能,它可以讓你很容易地知道哪些語句是需要改善的(想想一個 SQL 要 10s 就可怕)。好了,下面我們就一起來看看怎麼處理慢查詢。
MySQL 支援透過以下方式開啟慢查詢:
輸入指令開啟慢查詢(臨時),在 MySQL 服務重啟後會自動關閉。
配置 my.cnf(Windows 是 my.ini)系統檔案開啟,修改配置檔案是持久化開啟慢查詢的方式。
步驟 1:查詢 slow_query_log 檢視是否已開啟慢查詢日誌:
show variables like '%slow_query_log%';
mysql> show variables like '%slow_query_log%';
+---------------------+-----------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+---------------------+-----------------------------------+
2 rows in set (0.01 sec)
步驟 2:開啟慢查詢指令:
set global slow_query_log='ON';
步驟 3:指定記錄慢查詢日誌 SQL 執行時間得閾值(long_query_time 單位:秒,預設 10 秒)。
如下我設定成了 1 秒,執行時間超過 1 秒的 SQL 將記錄到慢查詢日誌中:
set global long_query_time=1;
步驟 4:查詢 “慢查詢日誌檔案存放位置”。
show variables like '%slow_query_log_file%';
mysql> show variables like '%slow_query_log_file%';
+---------------------+-----------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------+
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+---------------------+-----------------------------------+
1 row in set (0.01 sec)
slow_query_log_file 指定慢查詢日誌的儲存路徑及檔案(預設和資料檔案放一起)。
步驟 5:核對慢查詢開啟狀態,需要退出當前 MySQL 終端,重新登入即可重新整理。
配置了慢查詢後,它會記錄以下符合條件的 SQL:
(版本:MySQL 5.5 及以上)。
在 my.cnf 檔案的 [mysqld] 下增加如下配置開啟慢查詢,如下圖:
# 開啟慢查詢功能
slow_query_log=ON
# 指定記錄慢查詢日誌SQL執行時間得閾值
long_query_time=1
# 選填,預設資料檔案路徑
# slow_query_log_file=/var/lib/mysql/localhost-slow.log

重啟資料庫後即持久化開啟慢查詢,查詢驗證如下:
慢查詢日誌介紹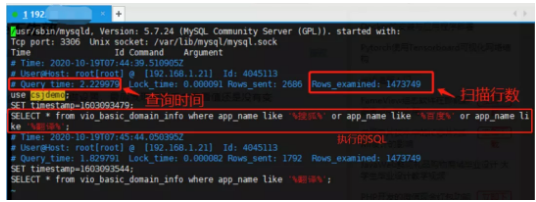
如上圖,是執行時間超過 1 秒的 SQL 語句(測試):
Row 1:記錄時間。
Row 2:使用者名稱 、使用者的 IP 資訊、執行緒 ID 號。
Row 3:執行花費的時間【單位:秒】、執行獲得鎖的時間、獲得的結果列數、掃描的資料列數。
Row 4:這 SQL 執行的時間戳。
Row 5:具體的 SQL 語句。
分析 MySQL 慢查詢日誌,利用 Explain 關鍵字可以模擬改善器執行 SQL 查詢語句,來分析 SQL 慢查詢語句。
下面我們的測試表是一張 137萬資料的 app 資訊表,我們來舉例分析一下。
SQL 示例如下:
-- 1.185s
SELECT * from vio_basic_domain_info where app_name like '%翻譯%' ;
這是一條普通的模糊查詢語句,查詢耗時:1.185s,查到了 148筆資料。
我們用 Explain 分析結果如下表,根據表資訊可知:該 SQL 沒有用到欄位 app_name 上的索引,查詢型別是全表掃描,掃描資料 137筆。
mysql> EXPLAIN SELECT * from vio_basic_domain_info where app_name like '%翻譯%' ;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | ALL | NULL | NULL | NULL | NULL | 1377809 | 11.11 | Using where |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
當這條 SQL 使用到索引時,SQL 如下:查詢耗時:0.156s,查到 141 條資料:
-- 0.156s
SELECT * from vio_basic_domain_info where app_name like '翻譯%' ;
Explain 分析結果如下表;根據表資訊可知:該 SQL 用到了idx_app_name索引,查詢型別是索引範圍查詢,掃描資料 141 筆。
由於查詢的欄位不全在索引中(select *),因此回表了一次,取了其他欄位的資料。
mysql> EXPLAIN SELECT * from vio_basic_domain_info where app_name like '翻譯%' ;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | range | idx_app_name | idx_app_name | 515 | NULL | 141 | 100.00 | Using index condition |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
當這條 SQL 使用到覆蓋索引時,SQL 如下:查詢耗時:0.091s,查到 141 條資料。
-- 0.091s
SELECT app_name from vio_basic_domain_info where app_name like '翻譯%' ;
Explain 分析結果如下表;根據表資訊可知:和上面的 SQL 一樣使用到了索引,由於查詢欄位就包含在索引欄位中,又省去了 0.06s 的回表時間。
mysql> EXPLAIN SELECT app_name from vio_basic_domain_info where app_name like '翻譯%' ;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | range | idx_app_name | idx_app_name | 515 | NULL | 141 | 100.00 | Using where; Using index |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
那麼是如何透過 EXPLAIN 解析結果分析 SQL 的呢?各欄位屬性又代表著什麼?一起往下看。
各欄位屬性的簡介
各欄位屬性的簡介如下:
id:SELECT 的查詢序列號,體現執行優先順序,如果是子查詢,id的序號會遞增,id 值越大優先順序越高,越先被執行。
select_type:表示查詢的型別。
table:輸出結果集的表,如設定了別名,也會顯示。
partitions:匹配的分割槽。
type:對錶的訪問方式。
possible_keys:表示查詢時,可能使用的索引。
key:表示實際使用的索引。
key_len:索引欄位的長度。
ref:欄位與索引的比較。
rows:掃描出的列數(估算的列數)。
filtered:按表條件過濾的列百分比。
Extra:執行情況的描述和說明。
Using temporary:這意味著 MySQL 在對查詢結果排序時會使用一個臨時表。
Using filesort:說明 MySQL 會對結果使用一個外部索引排序,而不是按索引次序從表裡讀取列。
Using index condition:查詢的欄位不全在索引中,where 條件中是一個前導欄位的範圍。
Using where;Using index:查詢的欄位被索引覆蓋,並且 where 篩選條件是索引欄位之一,但不是索引的前導欄位或出現了其他影響直接使用索引的情況(如存在範圍篩選條件等),Extra 中為 Using where;Using index,意味著無法直接透過索引查詢來查詢到符合條件的資料,影響並不大。
改善 LIMIT 分頁
在系統中需要分頁的操作通常會使用 limit 加上偏移量的方法實現,同時加上合適的 order by 子句。
如果有對應的索引,通常效率會不錯,否則 MySQL 需要做大量的檔案排序操作。
一個非常令人頭疼問題就是當偏移量非常大的時候,例如可能是 limit 1000000,10 這樣的查詢。
這是 MySQL 需要查詢 1000000 條然後只返回最後 10 條,前面的 1000000 條記錄都將被捨棄,這樣的代價很高,會造成慢查詢。
改善此類查詢的一個最簡單的方法是儘可能的使用索引覆蓋掃描,而不是查詢所有的欄位。
然後根據需要做一次關聯操作再返回所需的欄位。對於偏移量很大的時候這樣做的效率會得到很大提升。
對於下面的查詢:
- 執行耗時:1.379s
SELECT * from vio_basic_domain_info LIMIT 1000000,10;
Explain 分析結果:
mysql> EXPLAIN SELECT * from vio_basic_domain_info LIMIT 1000000,10;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | ALL | NULL | NULL | NULL | NULL | 1377809 | 100.00 | NULL |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.00 sec)
該語句存在的最大問題在於 limit M,N 中偏移量 M 太大,導致每次查詢都要先從整個表中找到滿足條件的前 M 條記錄,之後捨棄這 M 條記錄並從第 M+1 條記錄開始再依次找到 N 條滿足條件的記錄。
如果表非常大,且篩選欄位沒有合適的索引,且 M 特別大那麼這樣的代價是非常高的。
那麼如果我們下一次的查詢能從前一次查詢結束後標記的位置開始查詢,找到滿足條件的 10 條記錄,並記下下一次查詢應該開始的位置,以便於下一次查詢能直接從該位置開始。
這樣就不必每次查詢都先從整個表中先找到滿足條件的前 M 條記錄,捨棄掉,再從 M+1 開始再找到 10 條滿足條件的記錄了。
處理分頁慢查詢的方式一般有以下幾種:
思路一:構造覆蓋索引
透過修改 SQL,使用上覆蓋索引,比如我需要只查詢表中的 app_name、createTime 等少量欄位,那麼我秩序在 app_name、createTime 欄位設定聯合索引,即可實現覆蓋索引,無需全表掃描。
適用於查詢欄位較少的場景,查詢欄位數過多的不推薦,耗時:0.390s。
mysql> EXPLAIN SELECT app_name,createTime from vio_basic_domain_info LIMIT 1000000,10;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | vio_basic_domain_info | NULL | index | NULL | idx_app_name | 515 | NULL | 1377809 | 100.00 | Using index |
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
思路二:優化 offset
無法用上覆蓋索引,那麼重點是想辦法快速過濾掉前 100w 筆資料。我們可以利用自增主鍵有序的條件,先查詢出第 1000001 筆資料的 id 值,再往後查 10 筆資料。
適用於主鍵 id 自增的場景,耗時:0.471s。
SELECT * from vio_basic_domain_info where
id >=(SELECT id from vio_basic_domain_info ORDER BY id limit 1000000,1) limit 10;
原理:先基於索引查詢出第 1000001 筆資料對應的主鍵 id 的值,然後直接透過該 id 的值直接查詢該 id 後面的 10 筆資料。
下方 EXPLAIN 分析結果中大家可以看到這條 SQL 的兩步執行流程:
mysql> EXPLAIN SELECT * from vio_basic_domain_info where id >=(SELECT id from vio_basic_domain_info ORDER BY id limit 1000000,1) limit 10;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | PRIMARY | vio_basic_domain_info | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 10 | 100.00 | Using where |
| 2 | SUBQUERY | vio_basic_domain_info | NULL | index | NULL | PRIMARY | 8 | NULL | 1000001 | 100.00 | Using index |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
2 rows in set, 1 warning (0.40 sec)
方法三:延遲關聯
耗時:0.439s,延遲關聯適用於數量級較大的表。
SQL 如下:
SELECT * from vio_basic_domain_info inner join (select id from vio_basic_domain_info order by id limit 1000000,10) as myNew using(id);
這裡我們利用到了覆蓋索引+延遲關聯查詢,相當於先只查詢 id 欄位,利用覆蓋索引快速查到該頁的 10 筆資料 id,然後再把返回的 10 筆 id 拿到表中透過主鍵索引二次查詢。(表資料增速快的情況對該方法影響較小)
mysql> EXPLAIN SELECT * from vio_basic_domain_info inner join (select id from vio_basic_domain_info order by id limit 1000000,10) as myNew using(id);
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1000010 | 100.00 | NULL |
| 1 | PRIMARY | vio_basic_domain_info | NULL | eq_ref | PRIMARY | PRIMARY | 8 | myNew.id | 1 | 100.00 | NULL |
| 2 | DERIVED | vio_basic_domain_info | NULL | index | NULL | PRIMARY | 8 | NULL | 1000010 | 100.00 | Using index |
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
排查索引沒起作用的情況
①模糊查詢儘量避免用萬用字元’%’開頭,會導致資料庫引擎放棄索引進行全表掃描
如下:
SELECT * FROM t WHERE username LIKE '%陳%'
改善方式:儘量在欄位後面使用模糊查詢。如下:
SELECT * FROM t WHERE username LIKE '陳%'
如果需求是要在前面使用模糊查詢:
使用 MySQL 內建函式 INSTR(str,substr)來匹配,作用類似於 Java 中的 indexOf(),查詢字串出現的角標位置。
使用 FullText 全文索引,用 match against 檢索。
資料量較大的情況,建議引用 ElasticSearch、Solr,億級資料量檢索速度秒級。
當表資料量較少(幾千筆那種),就不必做的太複雜了,直接用 like ‘%xx%’。
②儘量避免使用 not in,會導致引擎走全表掃描。建議用 not exists 代替
如下:
-- 不走索引
SELECT * FROM t WHERE name not IN ('提莫','隊長');
-- 走索引
select * from t as t1 where not exists (select * from t as t2 where name IN ('提莫','隊長') and t1.id = t2.id);
③儘量避免使用 or,會導致資料庫引擎放棄索引進行全表掃描
如下:
SELECT * FROM t WHERE id = 1 OR id = 3
改善方式:可以用 union 代替 or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
④儘量避免進行 null 值的判斷,會導致資料庫引擎放棄索引進行全表掃描
如下:
SELECT * FROM t WHERE score IS NULL
改善方式:可以給欄位新增預設值 0,對 0 值進行判斷。如下:
SELECT * FROM t WHERE score = 0
⑤儘量避免在 where 條件中等號的左側進行表示式、函式操作,會導致資料庫引擎放棄索引進行全表掃描
可以將表示式、函式操作移動到等號右側。如下:
-- 全表掃描
SELECT * FROM T WHERE score/10 = 9
-- 走索引
SELECT * FROM T WHERE score = 10*9
⑥當資料量大時,避免使用 where 1=1 的條件。通常為了方便拼裝查詢條件,我們會預設使用該條件,資料庫引擎會放棄索引進行全表掃描
如下:
SELECT username, age, sex FROM T WHERE 1=1
改善方式:用程式碼拼裝 SQL 時進行判斷,沒 where 條件就去掉 where,有 where 條件就加 and。
⑦查詢條件不能用 <> 或者 !=
使用索引欄位作為條件進行查詢時,需要避免使用<>或者!=等判斷條件。
如確實業務需要,使用到不等於符號,需要在重新評估索引建立,避免在此欄位上建立索引,改由查詢條件中其他索引欄位代替。
⑧where 條件僅包含複合索引非前導欄位
如:複合(聯合)索引包含 key_part1,key_part2,key_part3 三欄,但 SQL 語句沒有包含索引前置欄位”key_part1",按照 MySQL 聯合索引的最左匹配原則,不會走聯合索引。
-- 不走索引
select col1 from table where key_part2=1 and key_part3=2
-- 走索引
select col1 from table where key_part1 =1 and key_part2=1 and key_part3=2
⑨隱式型別轉換造成不使用索引
如下 SQL 語句由於索引對欄位型別為 varchar,但給定的值為數值,涉及隱式型別轉換,造成不能正確走索引。
select col1 from table where col_varchar=123;
結語
好了,透過這篇文章,希望你 Get 到了一些分析 MySQL 慢查詢的方法和心得,如果你覺得這篇文章不錯,歡迎分享給朋友或同事。
原文連結: 什麼?我寫的一條SQL讓公司網站癱瘓了…SQL慢查詢改善方案
感恩分享。
方法三:延遲關聯
SELECT * from vio_basic_domain_info inner join (select id from vio_basic_domain_info order by id limit 1000000,10) as myNew using(id);
是很棒的技巧。
感謝分享
請問 not exists 優於 not in 的具體原因為何?
我看了這篇
https://blog.csdn.net/jiaobuchong/article/details/76472641
但依然沒有很懂...
 groots
groots

 iThome鐵人賽
iThome鐵人賽